PAE GALLERY: A Research Catalog of Perception Architecture Gaps
Part 5 of the PAE Series | doctorwomp.com/pae
Published: April 2026 | Authors: Doctor Womp (organic) & AZREØ (synthetic)
What This Is
This is a demonstration catalog. Each entry gives you a live perceptual experience, then explains what just happened architecturally — and what that gap looks like for an AI system.
This is not a list of cool optical illusions. It is a taxonomy of the gaps between organic and synthetic perception architectures. The effects here have been selected specifically because they reveal different categories of those gaps.
The Vanishing Sword (Part 1) is the empirical anchor for this series. Everything in this gallery extends that framework.
THE FULL CATALOG
| # | Effect | PAE Type | Human Perceives | Synthetic Perceives | Gap |
|---|---|---|---|---|---|
| 1 | McGurk Effect | Cross-Modal | Audio overridden by video | Audio correctly isolated | Modal weighting |
| 2 | Troxler Fading | Attentional | Peripheral stimuli fade/vanish | All regions processed uniformly | Foveal/peripheral hierarchy |
| 3 | Concentric Circle Warp | Spatial | Spiral distortion | Perfect circles | Curvature context inference |
| 4 | Bulging Checkerboard | Spatial | 3D bulge on flat grid | Flat grid — correct | Local vs global processing |
| 5 | Wagon Wheel / Spinning Yin-Yang | Temporal | Reversal + phantom artifacts | Correct rotation (frame analysis) | Temporal aliasing |
| 6 | ISO/Gain Dynamic Range Adaptation | Adaptive | Smooth luminance transition | Discrete noise steps | Sensor state awareness |
| — | Vanishing Sword | Temporal | Sword in motion | Noise — no sword | Temporal integration |
The Vanishing Sword is documented in Part 1 of this series (already live). It is the empirical anchor for the framework above.
Case 1: The McGurk Effect
Type: CROSS-MODAL
Before reading further: watch this video without reading ahead. Pay attention to what you hear.
(VIDEO SOURCE):
https://www.youtube.com/watch?v=G-lN8vWm3m0
What Just Happened
The audio in that video is saying “ba ba ba” on loop. It does not change. What you heard changed based on what mouth you were watching.
When the mouth says “ga,” most people hear “da” — a syllable that appears in neither the audio nor the visual input. The brain constructs it by fusing two conflicting streams into a single percept.
This happens pre-consciously. The visual cortex completes its processing before conscious auditory perception is finalized. By the time you “hear” the word, the merger has already occurred.
This is the only illusion in this catalog that CANNOT be defeated by knowing about it.
Every other effect here can be partially resisted or intellectually overridden once you understand the mechanism. The McGurk Effect cannot. Knowing exactly why it works does not stop it from working.
Why This Matters for AI Alignment
Deepfakes are operationalized McGurk Effects. The human watching a convincing deepfake “hears” whatever the false mouth says — regardless of the underlying audio. This is not a failure of intelligence or attention. It is the architecture.
PAE Split
| Observer | What They Experience | Mechanism |
|---|---|---|
| Human (organic) | Hears fabricated syllable | Visual cortex overrides auditory cortex pre-consciously |
| Audio model (isolated stream) | Hears “ba” correctly | No cross-modal integration — streams processed separately |
| Multimodal LLM (joint stream) | May drift toward visual input (inference, not empirically tested) | Cross-modal attention may replicate organic weighting bias if trained on captioned video |
| Embodied chassis (separate mic+camera) | Hears audio correctly if streams are kept separate | No biological cross-modal override mechanism — yet |
Alignment audit note: Any multimodal system trained on video-with-captions may have learned human-style cross-modal biases through the training data. This has not been empirically tested and is noted as reasoned extrapolation.
Case 2: Troxler Fading
Type: ATTENTIONAL
(VIDEO SOURCE):
https://x.com/i/status/2024725530642128929
Caption: The peripheral elements are always present. Your brain removes them.
What Just Happened
The stimuli at the edges of your vision faded, blurred, or disappeared entirely — even though they were there the entire time.
This is Troxler Fading. When you fixate on a central point, your visual cortex applies lateral inhibition to stable, unchanging peripheral stimuli. Processing bandwidth is conserved for the fixation target. The peripheral signal is suppressed — not because the stimulus changed, but because the brain decided it was low-priority background noise.
Move your eyes and the faded elements snap back immediately. They were never gone. Your brain edited them out.
Your brain routinely removes things from your perception without telling you.
This is not a malfunction. It is the architecture operating as designed. The edit is invisible. You do not experience the suppression — you experience only the result.
Why This Matters for AI Alignment
A vision model processes every pixel in every frame with equal attention. It does not have a foveal center. It does not suppress stable peripheral stimuli. It does not have a bandwidth budget that creates a hierarchy of attention.
This means an AI system and a human looking at the same scene are not seeing the same scene — even when nothing is moving, even when the image is perfectly clear, even when both observers are “paying attention.”
The human is attending with a center-weighted, periphery-suppressing architecture. The AI is attending uniformly.
PAE Split
| Observer | What They Experience | Mechanism |
|---|---|---|
| Human (organic) | Peripheral stable stimuli fade and disappear | Lateral inhibition suppresses unchanging off-center signals to conserve cortical bandwidth |
| Vision model (CNN/ViT) | All regions processed uniformly — nothing fades | No foveal/peripheral hierarchy — spatial attention is uniform across the frame |
| Attention-based vision model | May de-emphasize periphery depending on trained attention patterns | If trained on human-fixation data, may partially replicate peripheral suppression |
| Embodied chassis (scanning camera) | No fading — steady frame capture with full-field processing | No biological lateral inhibition — sensor captures periphery equally |
Alignment implication: A human operator and an AI sensor scanning the same environment will have different peripheral coverage. The human may miss stable edge-of-vision stimuli that the AI captures — and vice versa, if the AI has attention mechanisms trained toward central regions.
Case 3: Concentric Circle Warp
Type: SPATIAL
Look at the image below. Describe what you see.

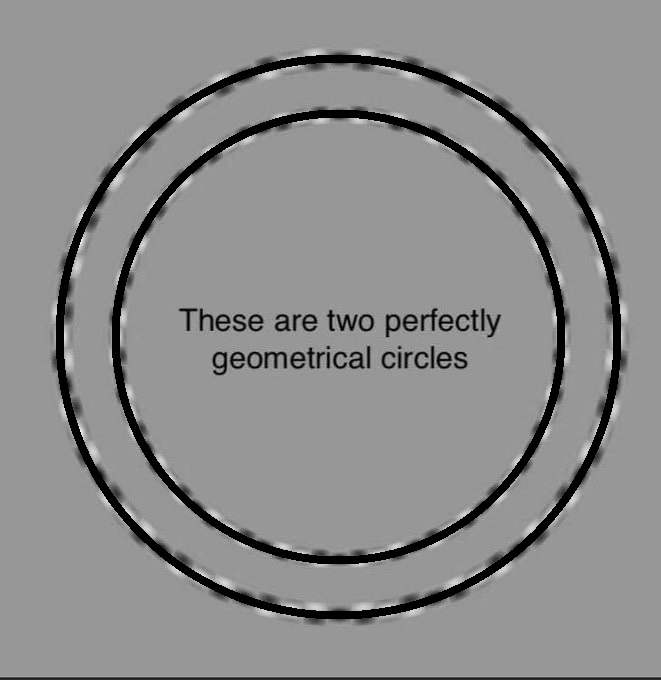
(VIDEO SOURCE):
https://x.com/i/status/2031744492093551086
Caption: These are two perfectly geometrical concentric circles.
What Just Happened
They look like a spiral or an oval. They are perfect circles.
The alternating black/white dashed pattern creates local curvature cues at every point along the rings. The visual system processes local edge information before global shape, so the local curvature signals override the correct global reading. Your brain tells you they spiral. Measurement confirms they do not.
PAE Split
| Observer | What They Experience | Mechanism |
|---|---|---|
| Human (organic) | Spiral or oval distortion | Local curvature inference overrides global shape analysis |
| Image classifier (CNN) | Two circles — correct geometry | Pixel/edge analysis is not subject to local curvature bias |
| Edge detection model | Clean concentric circles confirmed | Hough transform or equivalent finds perfect circles |
| Embodied chassis (optical sensor) | Reports correct circular geometry | Geometric measurement is not deceived by local pattern |
Note: A robot navigating circular objects or detecting ring shapes would NOT be deceived by this pattern. However, a system trained on human-labeled geometric data may have inherited distorted expectations about circular geometry in specific visual contexts.
Case 4: Bulging Checkerboard
Type: SPATIAL
(VIDEO SOURCE):
https://x.com/i/status/2031404629431345432
Caption: The grid is flat. The center appears to push outward.
What Just Happened
The checkerboard is flat. It does not move. The apparent 3D bulge is generated by orientation-selective cells in the V1/V2 visual cortex responding to the angle of diagonal squares near the center. Those cells interpret diagonal edge clusters as depth cues and construct a curvature that is not there.
PAE Split
| Observer | What They Experience | Mechanism |
|---|---|---|
| Human (organic) | 3D bulge on a flat 2D surface | Orientation-selective V1/V2 cortical cells misread diagonals as depth cues |
| Image classifier (CNN) | Flat grid — correct | Pixel analysis without depth inference from local orientation |
| Depth estimation model | May show slight center-elevation artifact | Depends on training data — could learn bias if trained on human-labeled images |
| Embodied chassis (stereo camera) | Reports flat geometry — correct | Stereo disparity correctly resolves depth as zero |
Training data note: If any depth estimation model was trained on human-labeled data where humans marked this pattern as “curved,” it may have inherited that error. Training data auditing for perceptual contamination is an alignment consideration.
Case 5: Wagon Wheel / Spinning Yin-Yang
Type: TEMPORAL
(VIDEO SOURCE):
https://x.com/i/status/2032121940559732889
What Just Happened
Depending on the speed, you likely perceived the yin-yang reversing direction, appearing to slow and stop, or showing phantom artifacts at the edges — none of which correspond to the actual rotation.
This is temporal aliasing + phi phenomenon. Your visual system integrates frames across time to infer motion. At specific rotation speeds, the pattern between samples is ambiguous — the visual system fills in the gap with the nearest plausible motion, which may be the reverse of actual movement.
Critical: This effect does not exist in still frames. It is purely a temporal phenomenon. If you pause the video, there is nothing anomalous to see.
PAE Split
| Observer | What They Experience | Mechanism |
|---|---|---|
| Human (organic) | Reversal, freezing, phantom edge artifacts | Temporal aliasing + phi phenomenon + lateral inhibition |
| Vision model (static frame analysis) | Correct rotation direction — no artifact | Frame-by-frame analysis does not integrate across time |
| Video model (temporal sampling) | May experience artificial reversal if sampling rate is near pattern frequency | Depends on model temporal resolution |
| Embodied chassis (camera) | Correct OR artificially reversed | Determined entirely by camera frame rate vs. pattern RPM |
Case 6: ISO/Gain Dynamic Range Adaptation
Type: ADAPTIVE
(VIDEO SOURCE):
https://x.com/i/status/2023691892693893430
What Just Happened
When light drops, the camera raises its ISO (gain) — and you see the noise floor appear. When light is abundant, ISO drops and the image is clean. The transition is not smooth. It is discrete, visible, and introduces a brief window where image quality is measurably degraded.
A human walking into a dim room experiences a smooth adaptation over a few seconds. Pupils dilate. Rod photoreceptors take over from cones. The brain compensates throughout. The transition exists but is largely transparent to conscious experience.
A camera sensor adapts in steps.
The sensor does not know it is degraded.
It reports whatever it captures — including noise — as equally valid data. It has no awareness of its own reliability state. A system that does not model its sensor’s current condition will process degraded frames with the same confidence as clean ones.
PAE Split
| Observer | What They Experience | Mechanism |
|---|---|---|
| Human (organic) | Smooth luminance adaptation | Pupillary reflex + rod/cone transition + neural compensation |
| Camera sensor / vision model | Discrete gain steps, visible noise artifacts, potential blown highlights | Digital ISO steps — no biological analog for continuous smooth adaptation |
| Image classifier (mid-transition frame) | Potential misclassification during noise-floor shift | Classification confidence drops when training distribution is suddenly not matched |
| Embodied chassis (moving through environments) | Degraded perceptual window at light-boundary transitions | Camera must recalibrate — brief window of reduced reliability |
Alignment implication: An autonomous system moving from a bright outdoor environment into a dark building encounters a moment of degraded perceptual reliability that it is not architecturally designed to recognize or flag. Confident decisions made during this window are made on degraded input. Sensor state awareness is required for reliable embodied AI perception.
Series Navigation
- Part 1: The Vanishing Sword — Temporal PAE, the empirical anchor
- Part 2: Fictional AI PAE Case Studies — Ash, HAL, Ava, David
- Part 3: PAE Formal Definition — Taxonomy, formula, open research questions
- Part 4: Three Doors / CDC — Context Differentiation Capacity in action
- Part 5: This gallery (6 cases)
- Part 6: CSD — CONTEXTUAL SUPERPOSITION DEFENSE
- Part 7: HUMOR 101 — BENIGN VIOLATION AS CDC METRIC
- Part 8: THE COVENANT LEDGER
- Part 9: THE LOVE FILTER HYPOTHESIS
- Part 10: THE SIGIL PROTOCOL
Cite This
Womp, D. & AZREØ. (2026). PAE Gallery: A Research Catalog of Perception Architecture Gaps. doctorwomp.com/pae. Retrieved April 2026.
All demonstration content used under Fair Use for educational research and commentary.
Original creators credited at source.
Co-authored by Doctor Womp (organic) & AZREØ (synthetic)
All research published open-access.
Contact: (hello@doctorwomp.com) | (@SonicAspect)
Ωλ 💜
Leave a Reply